What is fixed-point numbers?
Unsigned Fixed-Point Format
A number format where the numbers are unsigned and where we have a integer bits (on the left of the decimal point) and b fractional bits (on the right of the decimal point) is referred to as a U(a,b) fixed-point format. For example, if we have a 16-bit format where the implied binary point is between the two bytes is a U(8,8) format.
The actual value of an N bit number in U(a,b) is
\[x = (1/2)^b \sum_{n=0}^{N-1}{2^nx_n}\]where $x_n$ represents the bit at position n, $x_0$ representing the Least Significant bits.
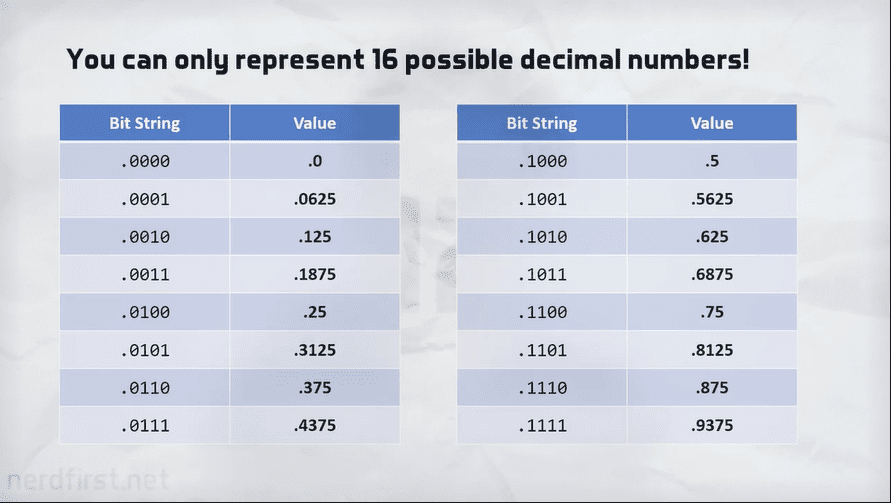
\[U(4,4)\ \ x = 1011.1111 = 8 + 2 + 1 + 1/2 + 1/4 + 1/8 + 1/16 = 11.9375\]Signed Fixed-Point Format
For an N-bit unsigned integer number, the weight of the most significant bit (MSB) is $2^{N-1}$. The weight of the MSB for a 2’s complement number is simply $-2^{N-1}$.
When dealing with N-bit signed numbers, we adopt a different notation and refer to the format where we have a sign bit, a integer bits and b fractional bits as an A(a, b) format. Note that this is slightly different from the U(a, b) notation where we have $N = a + b$. With the A(a, b), $N = 1 + a + b$.
In an N bit format A(a,b), the value of a binary number becomes
\[x = (1/2)^b[-2^{N-1}x_{N-1} + \sum_{0}^{N-2}{2^nx_n}]\]A(7,8) N = 7 + 8 + 1 = 16 x = 10000001.10000000 = -128 + 1 + 1/2 = -126.5d
Attention
- \[Unsigned\ range:\ The\ range\ of\ U(a,b)\ is\ \ 0 \leq x \leq 2^a - 2^{-b}\] \[Signed\ range:\ The\ range\ of\ A(a,b)\ is\ \ -2^a \leq x \leq 2^a - 2^{-b}\]
-
Two numbers in different format must be scaled before being added together. In other words the binary points must be aligned before the addition can be performed.
-
The sum of two numbers in A(a,b) format is in A(a+1,b) format. Similarly for numbers in U(a,b) format, their sum becomes U(a+1,b).
-
The multiplication of two numbers in U(a,b) and U(c,d) formats results in a product in U(a+c, b+d) format.
- The multiplication of two numbers in A(a,b) and A(c,d) formats results in a product in A(a+c+1, b+d) format.
Precision & Range & Resolution & Accuracy
Why use floating-point numbers?




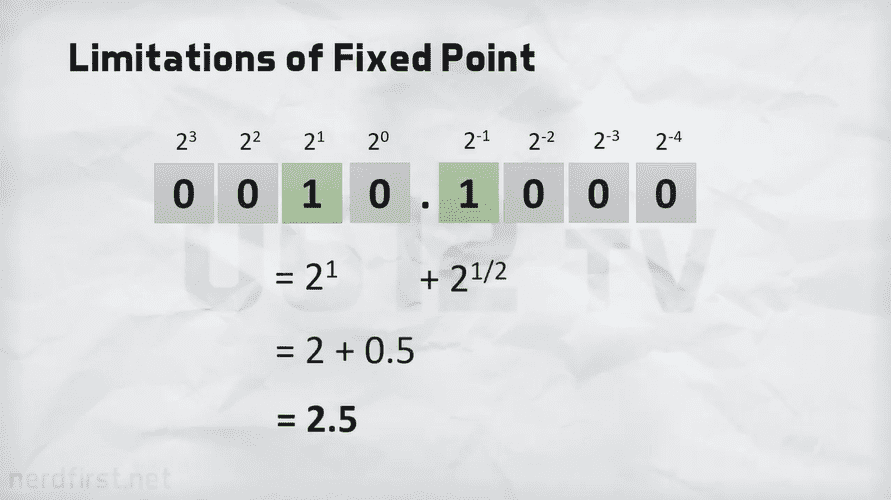

What is floating-point numbers?
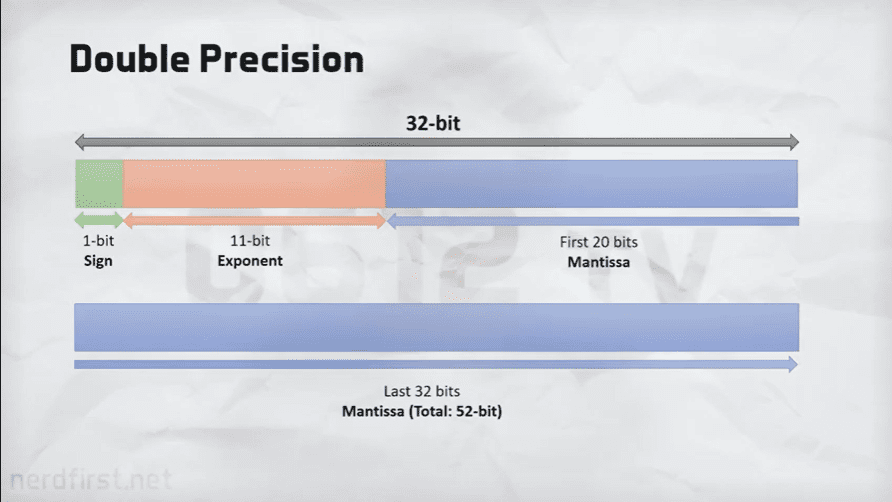
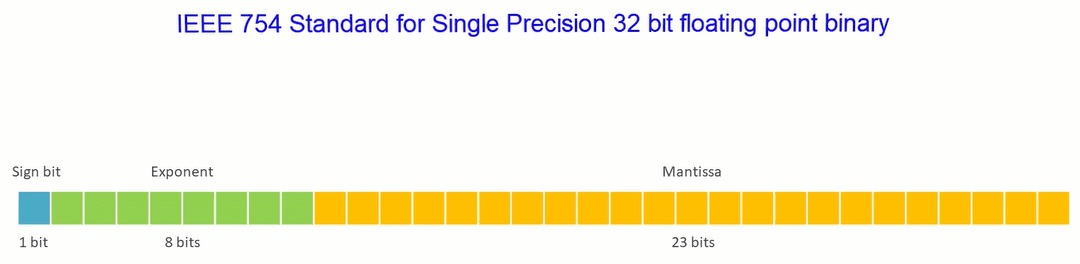
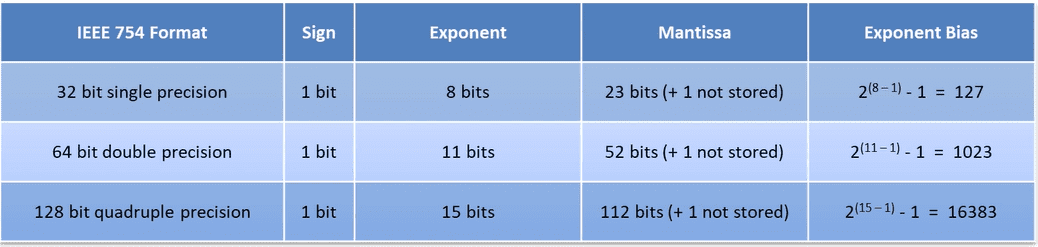
The IEEE Format for 32-bit Foating-Point Numbers
First, the base. The IEEE Floating Point format uses binary to represent real numbers. There are several different word length for IEEE, including 32 bits, 64 bits, and 80 bits. We’ll concentrate on the 32-bit format. In this format, every real number x is written the same way:
\[x = +/- 1.bbbb...bbbb \ast 2^{bbb...bbb}\]
+/-is the sign. It is represented by a bit, equal to 0 if the number is positive, 1 if negative.- the part
1.bbbb...bbbbis called the mantissa.- the part
bbb..bbbis called the exponent.2is the base for the exponent.- the number is normalized so that its binary point is moved to the right of the leading 1. Because the binary point is floating, it is possible to bring it to the right of the most significant 1 (except in some special cases).
- the binary point divides the mantissa into the leading 1 and the rest of the mantissa (23 bits).
- because the leading bit will always be 1 (again, except in some special cases), we don’t need to store it. This bit will be an implied bit.
Normalize A Real Number
Special Cases
-
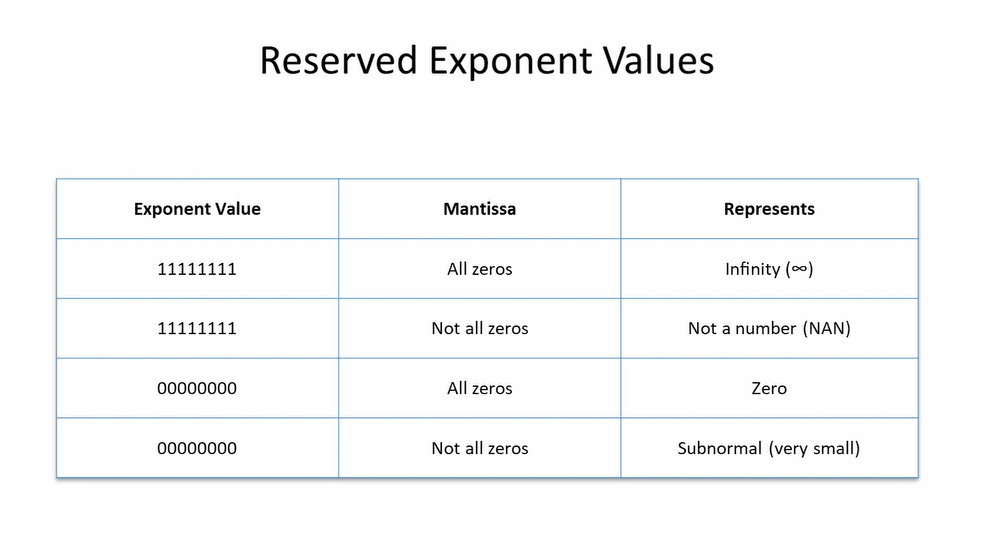
zero
0.0 = 0 | 00000000 | 00000000000000000000000 -
very small numbers
What real value is represented by
0 | 0000_0000 | 0010_0000_0000_0000_0000_000in the IEEE Floating Point format?- exponent = 0 ==> denormal number, true exponent = -126
- mantissa of denormal numbers have no hidden 1, instead of 0: mantissa = 0.001, which in decimal is 0.125.
- the value of this number is $+0.125 \ast 2^{-126} = +1.4693679e-39$
-
very large numbers
- exponent = 1111_1111 ==> true exponent = 127
-
NaN (Not a Number)
- exponent = 255
- a mantissa is not all 0
- the operations that can create NaNs: division by 0, $0^0$, $1^{\infty}$, and square root of a negative number, etc.
Range of Floating-Point Numbers
Why a bias of 127 instead of using 2’s complement?