如何用Python来爬取网络图片?
本篇文章对应的项目地址:https://github.com/liangchen01xz/pics_crawler_prj
框架:Scrapy
例子:要求从煎蛋网上爬取所有妹子图片
涉及的知识:
urllib.request、pickle、re、Xpath
Scrapy工作原理1
-
Scrapy架构图(绿线是数据流向)
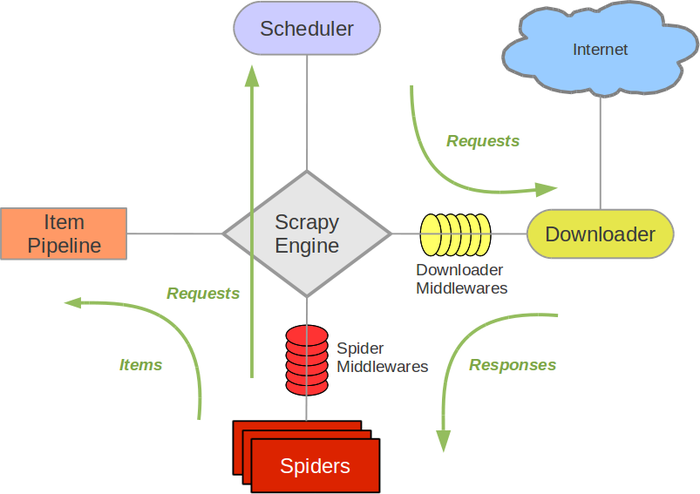
- Scrapy Engine(引擎)
- Scheduler(调度器)
- Downloader(下载器)
- Spider(爬虫)
- Item Pipeline(管道)
- Downloader Middlewares(下载中间件)
- Spider Middlewares(Spider中间件)
准备工作
-
安装Scrapy
windows安装方式:
-
升级pip版本:
pip install --upgrade pip -
安装Scrapy:
pip install Scrapy
其他环境安装方式:
请自行Google
-
-
安装Pillow
-
pip install Pillow -
否则在启动Crawl时会出现错误:
ModuleNotFoundError: No module named 'PIL'
-
-
代码风格
- 一定要确认代码缩进是制表符,不是空格符,否则在启动Crawl时会出现错误:
TabError: inconsistent use of tabs and spaces in indentation
新建项目
进入自定义目录,在cmd窗口中运行命令:
scrapy startproject imgs,会创建一个名为imgs的新文件夹,新文件夹目录结构大致如下:
imgs/ scrapy.cfg // 项目配置文件 imgs/ // 项目的Python模块,从这里引用代码 __init__.py // 初始魔法方法,不用管 items.py // 项目目标文件 pipelines.py // 项目管道文件 settings.py // 项目设置文件 spiders/ // 爬虫代码目录 __init__.py ...
编写目标文件
items.py
编写管道文件
pipelines.py
照葫芦画瓢即可,具体解释看这里:scrapy爬取图片示例
编写设置文件
settings.py
其他设置代码的意义请自行Google
制作爬虫
-
新建一个spider:
scrapy genspider jandan "jandan.net";生成的文件在spiders文件夹下得到的模板代码如下:
1 2 3 4 5 6 7 8 9 10 11
# -*- coding: utf-8 -*- import scrapy class JandanSpider(scrapy.Spider): name = 'jandan' allowed_domains = ['jandan.net'] start_urls = ['http://jandan.net/'] def parse(self, response): pass
name = "":爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字allow_domains = []是搜索的域名范围,规定爬虫只爬取这个域名下的网页start_urls = []:爬取的URL元祖/列表,爬虫从这里开始抓取数据,其他子URL将会从这些起始URL中继承性生成parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:负责解析返回的网页数据(response.body),提取结构化数据(生成item)
生成需要下一页的URL请求
-
分析目标网页:
- 我们需要爬虫模拟的动作有两个:
- 一个是从初始页面点击【下一页】,得到下一个待爬取的网页地址;
- 二是得到每一页所有图片的下载地址;
- 我们需要爬虫模拟的动作有两个:
-
第一个动作中得到的每一个网页地址加上初始网页地址就是
start_urls = []的值,显然我们可以发现需要爬取的网页有一百多页,不可能自己一个一个地手动输入,这样我们还要爬虫干嘛?所以有了下面的代码,你需要了解urllib.request2模块,pickle3模块和lxml中的 etree[^4]:page_addrs.py1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
import urllib.request import pickle from lxml import etree def get_page(url): req = urllib.request.Request(url) req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36') response = urllib.request.urlopen(url) html = response.read().decode('utf-8') htmlx = etree.HTML(html) try: page_addr = htmlx.xpath('//*[@title="Older Comments"]/@href')[0] page_url = 'http:' + page_addr addrs.append(page_url) return get_page(page_url) except IndexError: with open('page_addrs.pkl','wb') as f: # 以二进制格式写入!!! pickle.dump(addrs, f) f.close() if __name__ == '__main__': url='http://jandan.net/ooxx' addrs=['http://jandan.net/ooxx'] get_page(url)
补充关于HTML的知识:学爬虫利器XPath,看这一篇就够了
强烈建议用
*号代替html中的路径节点,比如上面代码的第14行[^4]:一个 xpath解析库
-
jandan.py(在spiders文件夹下)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
# -*- coding: utf-8 -*- import scrapy from imgs.items import ImgsItem import pickle import re class JandanSpider(scrapy.Spider): name = 'jandan' allowed_domains = ['jandan.net'] with open('page_addrs.pkl', 'rb') as f: # 这里一定要以二进制格式读出!!! start_urls = pickle.load(f) f.close() def parse(self, response): str1 = str(response.body) list1 = re.findall(r'comment-4.{6}', str1) set1 = set(list1) list2 = list(set1) for each in list2: img_addr = response.xpath('//*[@id="' + each + '"]/div/div/div[2]/p/img/@src').extract()[0] img_url = 'http:' + img_addr img_name = img_url.split('/')[-1] myitem = ImgsItem() myitem['imgs_url'] = [img_url] # 这里一定要写成列表形式[]!!! myitem['imgs_name'] = img_name yield myitem
补充正则表达式的知识:learn-regex 关于
re模块:菜鸟教程
启动爬虫
-
首先把
page_addrs.py脚本放在项目目录下,执行该脚本,会得到一个包含了所有页面地址的数据文件page_addrs.pkl如下:
注意一定要将该文件放在这个路径位置:
1 2 3 4 5 6 7 8 9 10 11
imgs/ ***page_addrs.pkl*** scrapy.cfg imgs/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ...
-
启动爬虫:
scrapy crawl jandan,得到最终结果: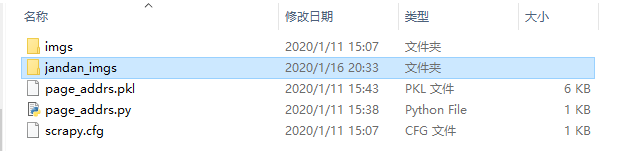
打开这个文件夹可以看到图片已经开始下载,(截取一部分):

等待一段时间,所有图片下载完毕。。。